TL;DR: I made a small artifact to look at what optimizers actually do to updates during training. It logs a bunch of update geometry metrics over nanoGPT training runs, then lets you poke through them by optimizer, layer, and time.
As part of my goal to deepen my intuition for each layer of the AI stack, I messed around with nanoGPT and Muon a few months back with Abel Gurung. I revisited that thread after seeing some of the recent discourse around Shampoo vs Muon -- I was especially curious to see the different kinds of update geometry induced by different optimizers.
I decided to do this audit on top of track 3 of the modded-GPT challenge. More specifically -- for each parameter during nanoGPT training, I recorded the parameter + gradient before the optimizer step and the parameter after the step. This let me extract the update:
It is worth noting that this isn't the pure update. It still folds in momentum, learning rate, weight decay, etc. I wasn't able to find a generalizable way to isolate just the preconditioning effect (Claude and Codex couldn't either). Most speedrun submissions tune those hyperparameters per-run anyway, so I think it's fine to eat that variable for now. Now that we have the effective update , let's try tracking a few rough diagnostics on it!
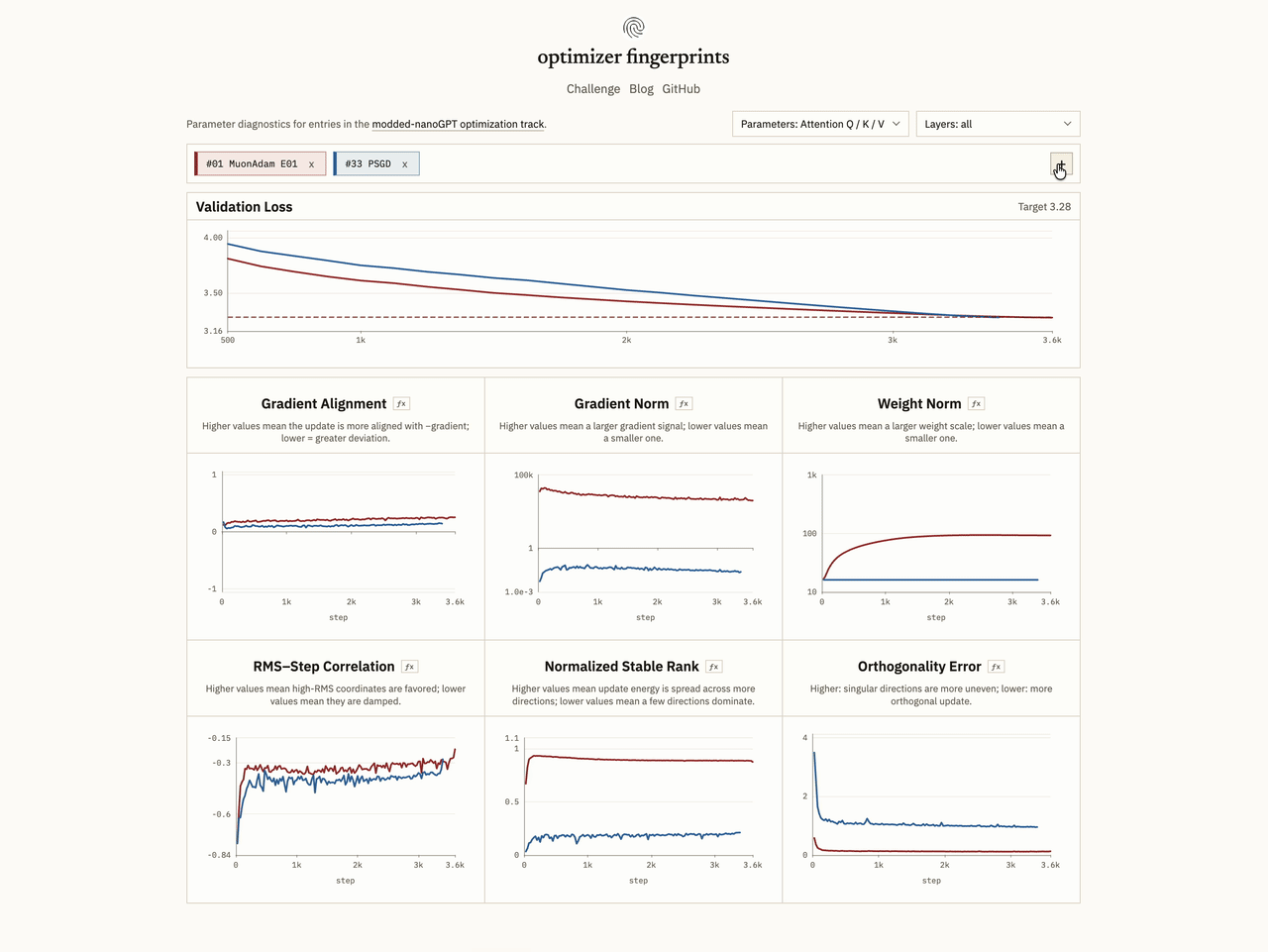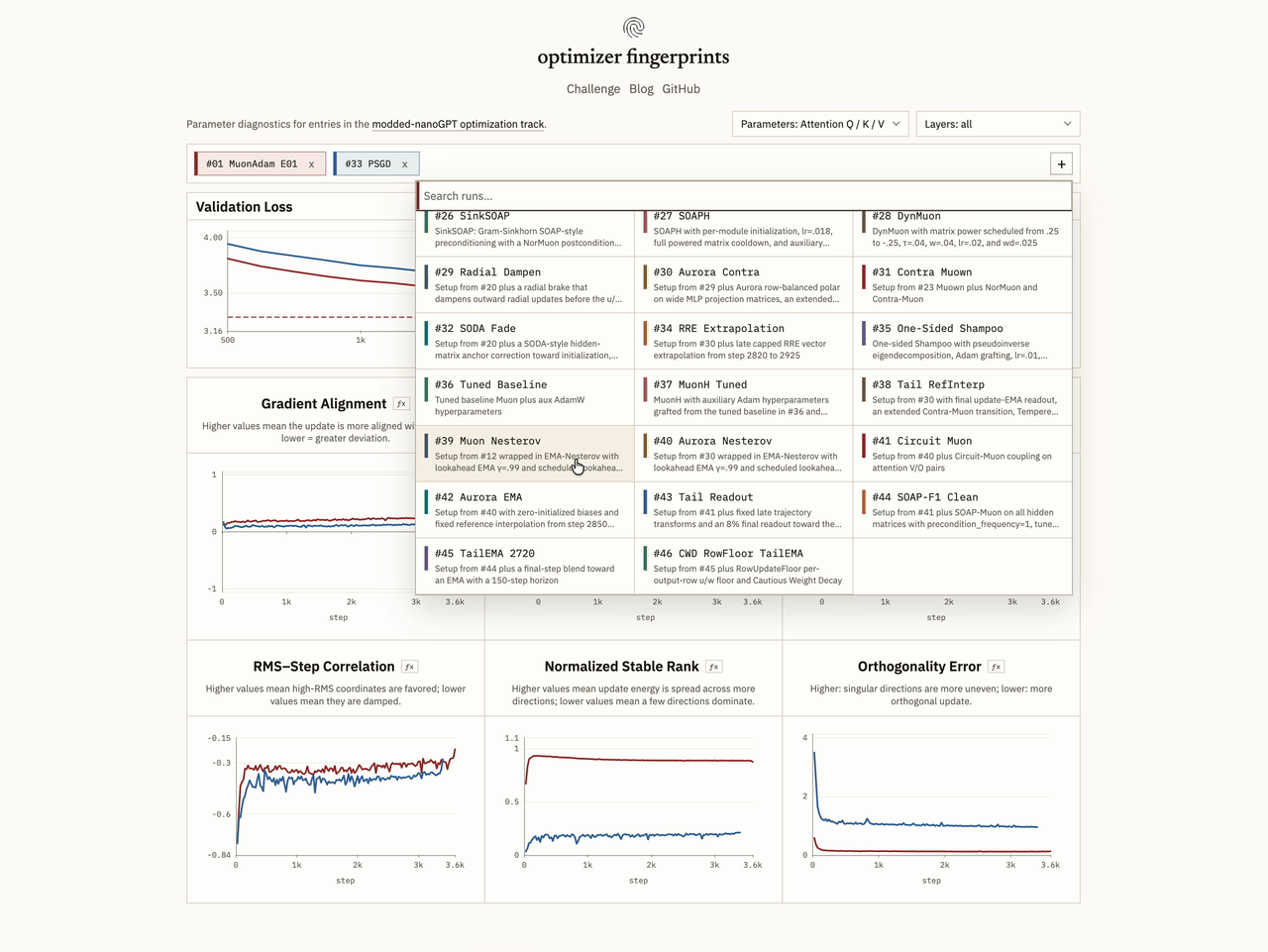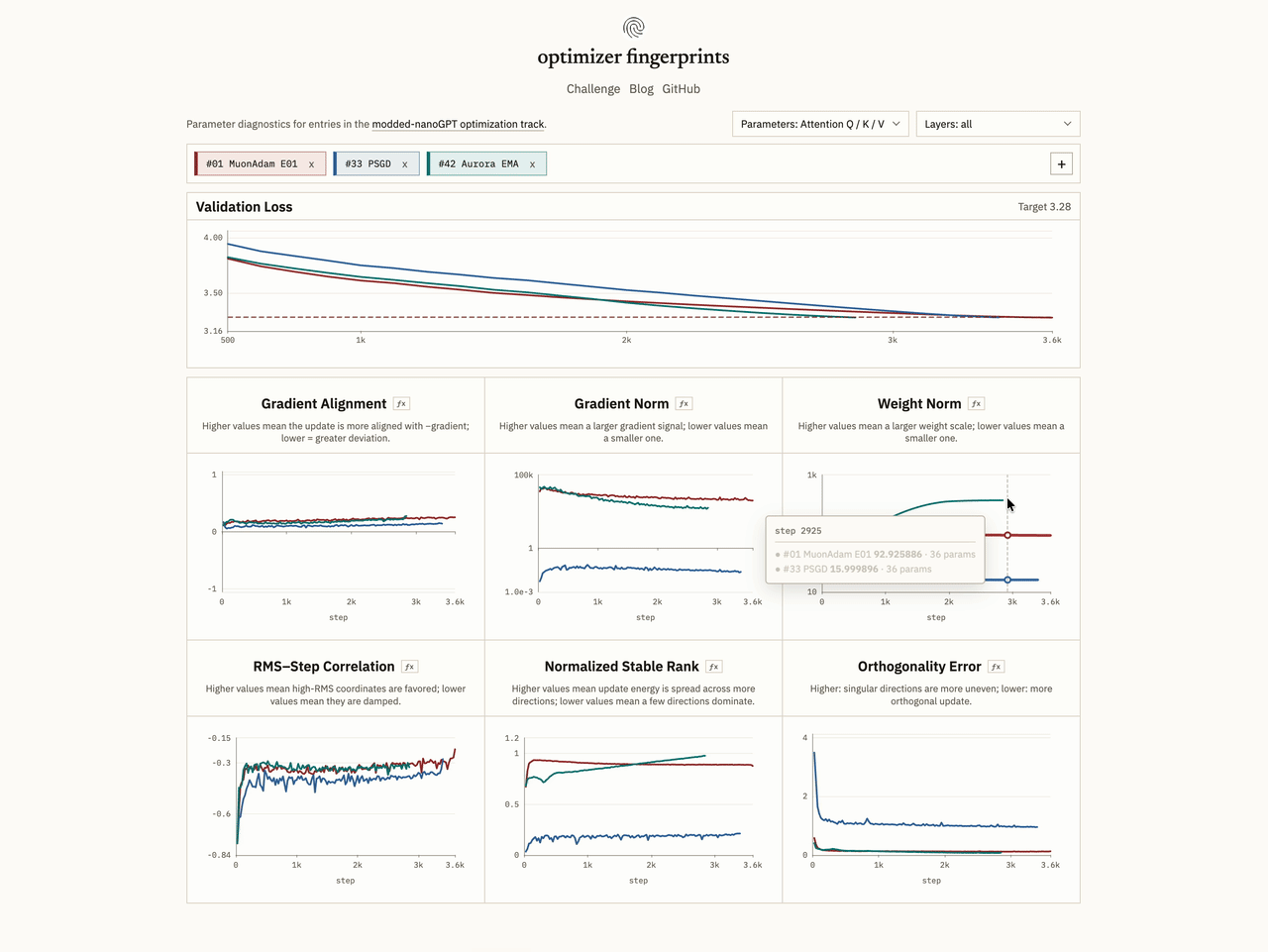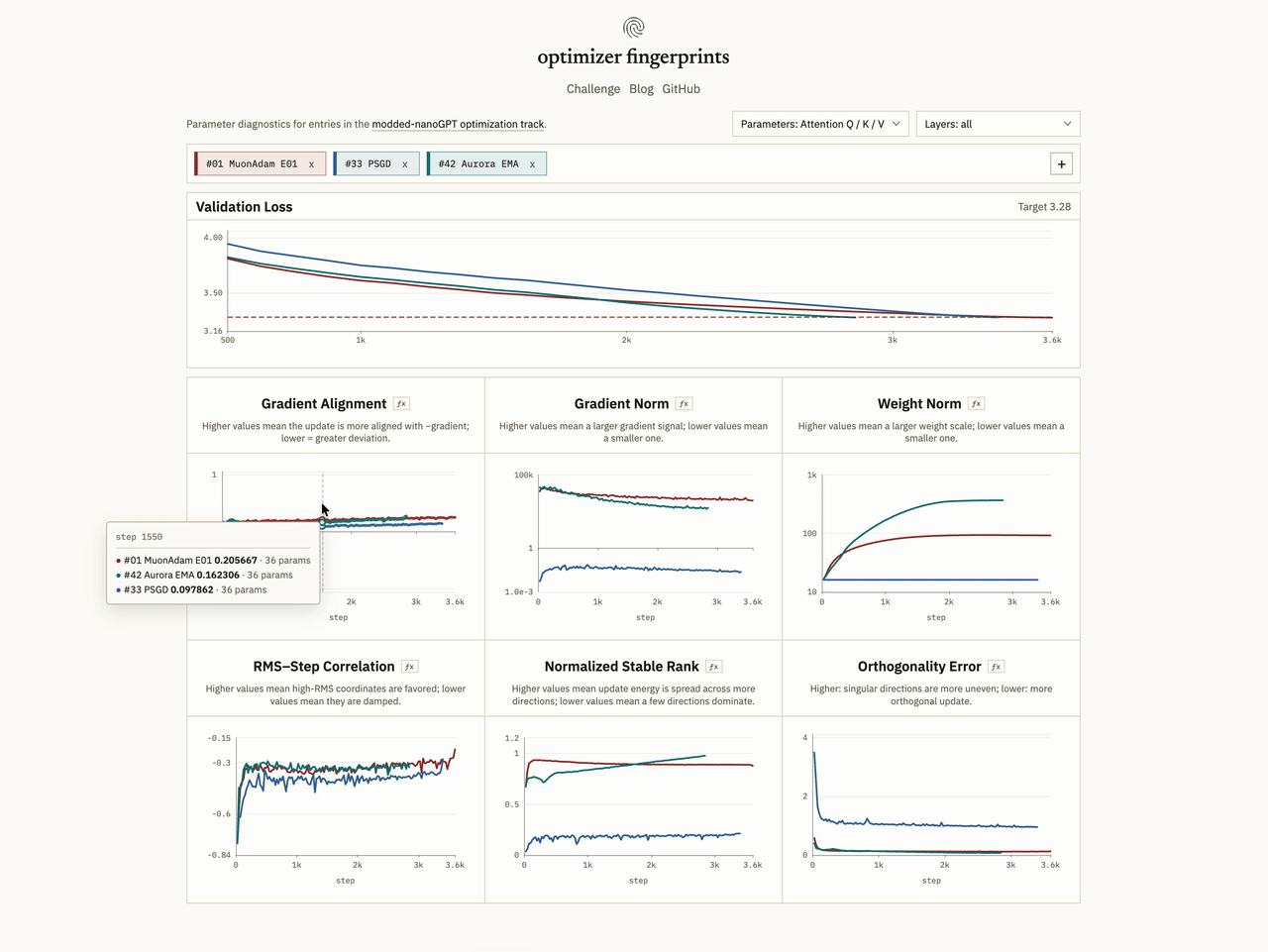
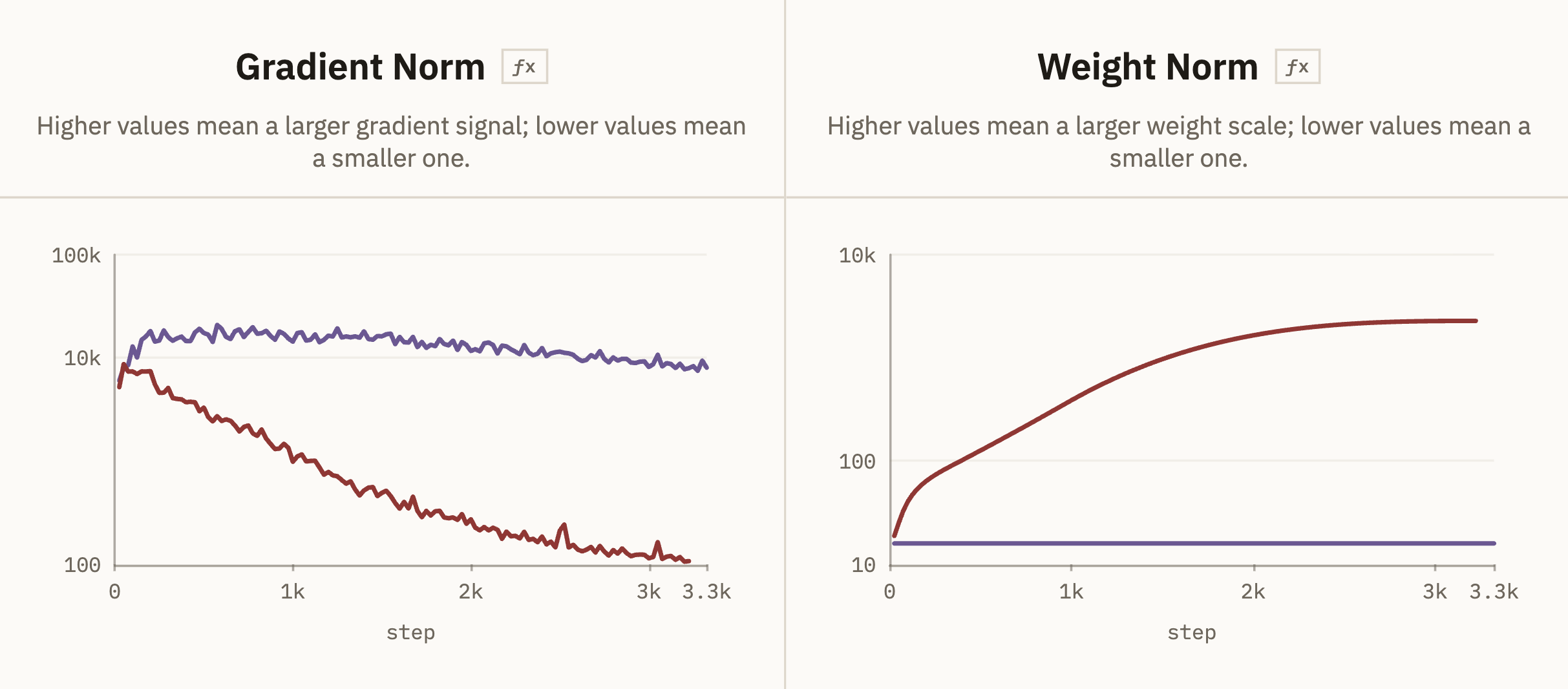
Firstly, we can simply track gradient norm and weight norm for scale context. If one run has much larger weights or gradients, I'd want to know that before reading too much into anything else.
A nice example is MuonH vs ContraMuon: MuonH keeps hidden matrix weights on a fixed Frobenius radius by projecting after each step, so stays basically constant. Contra Muon does not constrain the weight radius; instead it floors the relative update size, roughly . So in that run, can grow dramatically while actually falls, because the optimizer controlls the update scale.
We can also track relative direction, i.e. if the update is close to the negative descent direction. For this, we can compute the cosine similarity between the raw gradient and the update:
A nice example for direction is AdamW vs SOAPH:
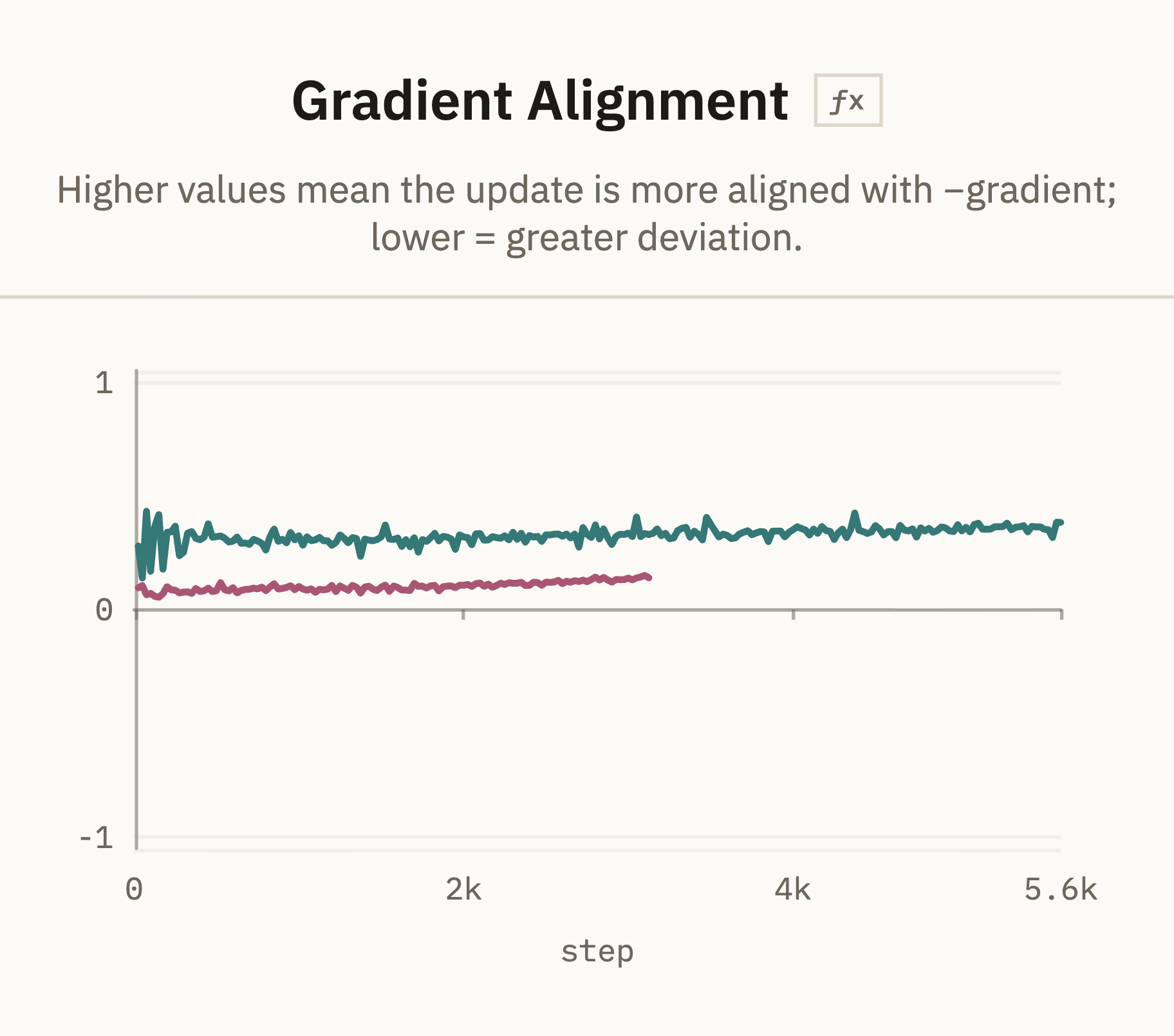
AdamW is mostly a per-coordinate rescaling of the gradient plus momentum/decay, so its update tends to stay relatively aligned with the raw negative gradient. SOAPH is much less aligned, which is expected because SOAP/Shampoo-style methods precondition the matrix update and can rotate it substantially before stepping.
We can also ask whether the optimizer is doing something Adam-like coordinatewise. Adam rescales each coordinate by its historical gradient RMS, damping high-RMS ones relative to low-RMS ones. To check if this is showing up in the effective update, we track the correlation between the log RMS and the log step-to-gradient ratio:
means high-RMS coordinates are getting favored; means they're being suppressed, which is the Adam-like behavior. A representative example here is AdamW vs Shampoo:
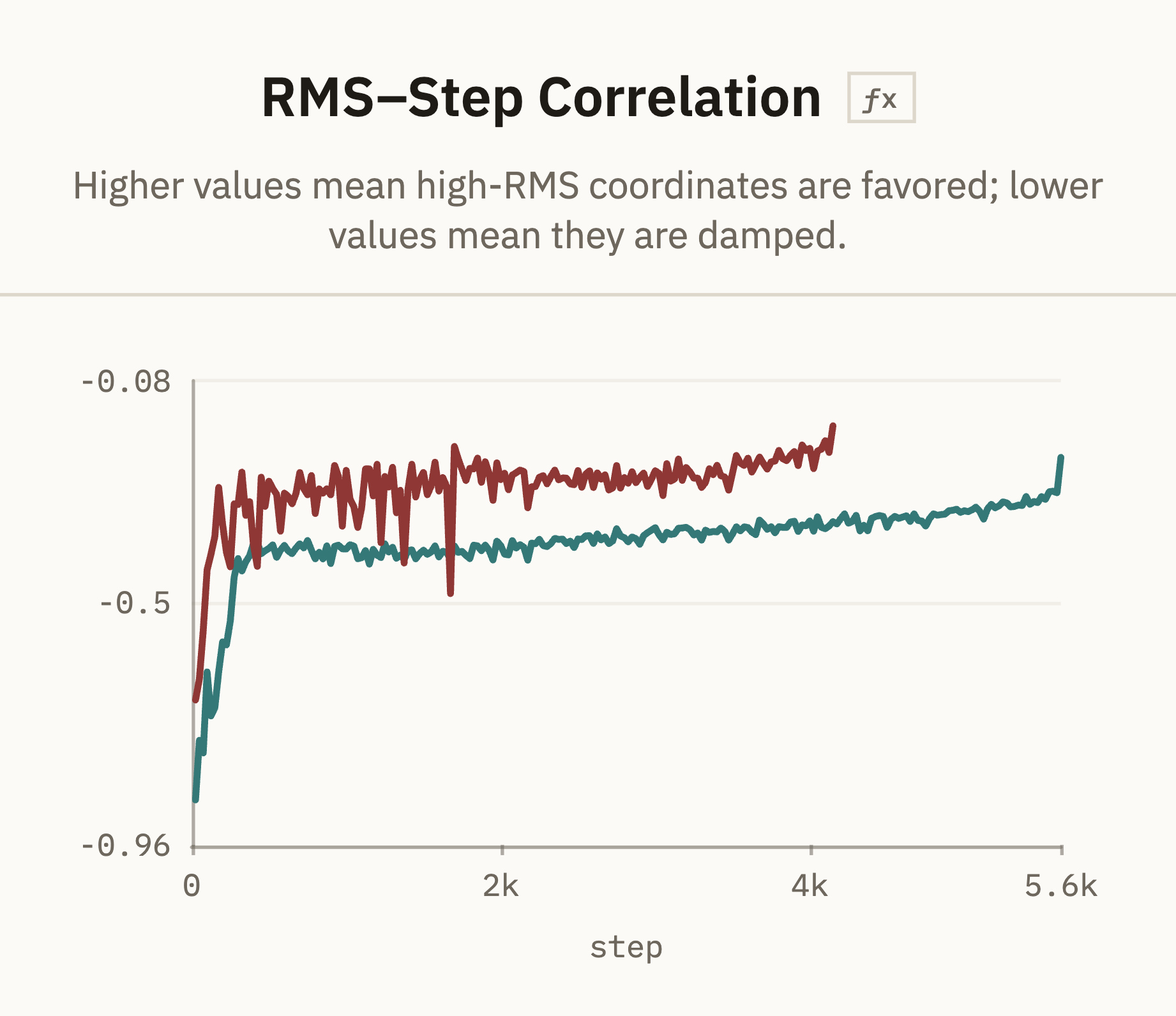
AdamW should be the boring reference case for this metric (this is directly aligned to its update) Shampoo is different. It is still an adaptive optimizer, but its preconditioner is matrix-shaped rather than coordinate-shaped. The suppression is still visible, but weaker:
Finally, since a lot of the recent discourse is about matrix structure -- Muon, Shampoo, orthogonalized updates -- we can look at the geometry of the update matrix directly. Normalized stable rank asks whether the update energy is spread across many singular directions or dominated by a few:
Stable rank is a softer version of raw rank that weights directions by how much energy they carry, which conveys a much more meaningful picture of how spread out the update actually is. Values close to 1 mean energy is spread evenly; lower values mean a handful of directions dominate.
Orthogonality error checks how close the update is to a scaled orthogonal matrix:
For example -- AdamH’s QKV updates have low normalized stable rank and high orthogonality error, so most of the update energy is concentrated in a few singular directions. Muon looks completely different (as expected):
I don’t think any one of these metrics explains why an optimizer works, and this is definitely not a clean isolation of preconditioning. But even through all the messiness, the update fingerprints seem to have fairly informative variation! Mostly, this helped me build better intuition for what these optimizers do during training -- hopefully it does the same for you.
You can play with the data here, and if you have ideas for new metrics or features, PRs are very welcome :)